 By
By Co-funded by the European Union Horizon 2020 Research and Innovation Programme, ARDITO is a project aimed at providing simple tools and services to support SMEs in the creative content sector to find new business ideas through monetising the re-use of their content.
Building on existing e-infrastructures tested in the earlier European Union co-funded project RDI – Rights Data Integration, rights data standards and content identifiers, ARDITO brings together a group of well-established SMEs from different creative sectors (book and journal publishing and images: mEDRA, Icontact and Album) with a research centre developing tools for the audio-visual sector, b<>com, and the Copyright Hub Foundation, to fill the gap in the digital content value network and connect online contents to rights information, by building a complementary digital “Rights Data Network”.
The aim is to communicate to final users how creative content can be exploited by automatically linking content assets to rights information and services in the digital environment.
The core of ARDITO tools allowing the automatic linking are the identification technologies (IDs embedded in content as watermarks, content recognition by digital pattern matching, Web resolvable content IDs based on DOI standard technology) integrated with the Copyright Hub ecosystem: this combination allows content owners to easily express information about the rights of use and re-use of their assets and to automatically provide final users with seamless access to such data, for them to discover the rightsholder of the content and the available re-use licenses (e.g. to copy a part of an e-book, to post an image or a video in a blog etc.).
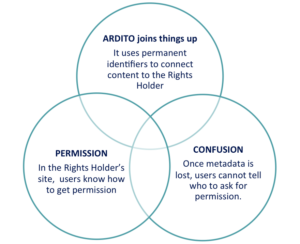
The ARDITO idea in a nutshell
By developing these tools, ARDITO enables multiple services across the different market segments it covers in the creative industry that share the same vision: to be an access point to rights information and related services for different content types, while supporting the growth of the SME sector.
The ARDITO project kicked off in February 2017 and has a total duration of 18 months. Along the project life time, project partners will develop tools enabling added value services to be integrated in their business lines, in order to be directly offered to their customers, and in the same time will outreach project outcomes to the SMEs and other organisations in the creative content industry for them to increase their business opportunities.
Business needs
Over the past twenty years there has been an unprecedented explosion in the volume and types of digital creative content: from e-books, music streaming and games, to online news and entertainment hubs and video-on-demand platforms. Everything is digital today, from the production process to the products and the supply chains, to the way in which digital products and services are made available to end users. Nonetheless, there is a “dark lacuna” when it comes to the digital rights information discovery in the content value chain: when end users wish to re-use creative content, it is hard to find information about who to ask for permission, which licenses are available, and on which terms and conditions.
The complexity of seamlessly integrating such rights information in the supply chain depends on several factors:
- the lack of tools for content producers (e.g. authors, publishers) and providers (e.g. licensors) to easily produce rights data and to integrate it in the supply chain;
- the loss of such rights data due to the manipulation of content metadata along the supply chain, that makes it difficult to track back to the original owner;
- the prevalence of big players that dominate the digital content supply chain with powerful and often proprietary tools.
It is clear that actual functioning of the rights supply chain needs to be empowered in order to make it easier – particularly for SMEs that represent 85% of all actors in the creative industry sector and often lack of technological infrastructures – to enable the proper use and re-use of assets and in perspective to create new revenue streams through secondary content licensing (e.g. re-publication of images, embedding of videos in third parties content, copy of pieces of books and journal articles etc.). On the content consumer side, the increased availability of and simple access to rights data would help grow the lawful exploitation of content assets and facilitate the user experience as far as discoverability of content information is concerned.
To fulfil these needs (i.e.: empowered rights supply chain, increased user access to rights data and lawful content consumption), it is crucial to build a “rights data network”, a network of connected e-infrastructures to:
- automate the exchange of information about rights between owners and users;
- empower existing services for rights management;
- create new business opportunities through monetising the re-use of content.
This is where ARDITO tools come into play.
Solutions
The vision of ARDITO is that any content provider (particularly SMEs) should be able to easily communicate rights information about content, and any user should be able to easily access to such data in order to understand how the content can be used. The ARDITO solution is designed to provide an interoperable mechanism through which rights data can be consistently and efficiently discovered in digital environments: in order to achieve this goal, the value proposition of ARDITO is to build this mechanism using existing identification technologies, integrating them in a common ecosystem and developing new connected services.
Identifiers are the ID cards of content and a trustworthy information carrier, therefore they are a key tool for creating automated connections between content and related information: the core of ARDITO principles is that if content can be identified, users can find where to ask for permission of use/re-use. The content identification technologies that ARDITO is exploiting cover IDs embedded in e-books and audio-visual content as watermarks, content recognition by digital pattern matching, Web resolvable content IDs based on DOI standard technology. These different identification methods are optimised in order to be integrated with the Copyright Hub platform, that serves as a central index of information helping rights data communication for content creators/producers and rights data discovery for end users.
As final result, ARDITO partners will provide the market with new services based on the combination of the identification technologies and the Copyright Hub platform to be directly exploited, but that can also be integrated in other systems (e.g. services for rightsholder, content producers systems etc.):
- a service for image collections, archives, newspapers, publishing companies, based on enhanced content recognition technology to link images retrieved through Web crawling to rights data and connected services, provided by the picture agency Album;
- services for audio-visual producers, e-book publishers, book shops and distributors based on enhanced watermarking technologies, to identify digital content in the audio-visual and text sector (e-books) and link directly from the content file to rights data and services, provided respectively by b<>com Institute of Technology and by the digital watermarking solution provider Icontact;
- a toolkit for publishers, self-publishers and DOI users, based on DOI system, to create, display and connect rights data, rights declarations and services to content identifiers (ISBN-A and DOI), provided by the R&D company and DOI registration agency mEDRA.
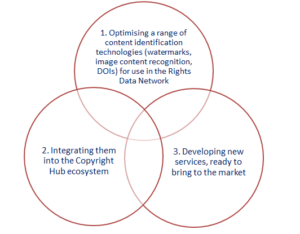
The ARDITO solution in a nutshell
In ARDITO ecosystem, each source of rights information (e.g. content owners, rightsholders, licensing agencies, rights management platforms etc.) exploits the services described above in order to automatically connect the content rights data through the Copyright Hub, that provides a central index for rights information retrieved anywhere on the Web; when users on the Web find content they are able to reach rights information in one click, thanks to the Copyright Hub Web browser plug-in or inline links that automatically query the Copyright Hub.

The website www.ronburtonphotographer.com is connected to the Copyright Hub and displays the e-Copyright symbol on the images. With a click, users directly go to the license options for the selected image.
At the end of the value chain users of creative content, when clicking on an image, when finding the identifier of a textual content (ISBN-A or DOI), when reading an e-book or watching a video, will be enabled to access services that provide rights data about that content, including:
- how to find rightsholders easily wherever content is found;
- how to re-use the content in a different context;
- how to get permission for re-use.
The role of technology
ARDITO technical framework comprises a network of technologies applied to different content types – images, audio-visual products, e-books and journals.
The technologies covering the image sector have been developed by Album in order to enable exact image content recognition through a Reverse Image Search tool (RIS), combined with a Visual Web Crawler:
- the RIS enables a user to perform a search within an image collection hold by Album directly from an image file, even if the file has been modified (cropped, rotated etc.);
- the Crawler is a distributed architecture system constantly exploring the Web: every image found is searched against the RIS index and matching images and crawling information are stored in the crawler database.
The new crawling service that finds sets of images across the Web will be integrated into the Copyright Hub environment through a CH-Crawler Communication Protocol that governs the access to the Crawler, the indexing of images to be searched by the Crawler and the querying of crawl results, obtaining matched images and related information for final users.
The audio-visual sector will benefit of a technology of video watermarking by b<>com, the Ultra Marker technology in base band domain, compatible with any video encoding format and designed to fine tune the trade-off between robustness and watermark code length (the amount of data to be embedded). The Ultra Marker will be exploited as a SaaS whereby:
- rightsholders upload content to Ultra Marker platform;
- define technical video parameters (codec, bitrate etc.) and rights available for video content;
- once the watermark embedding is completed, Ultra Marker e-mails the URL with watermarked video to the rightsholder;
- through the Copyright Hub plug-in or inline links, the Copyright Hub is able to query Ultra Marker and read the video URL, returning permission sets to final users.
In the book sector, Icontact will extend the existing watermarking service for e-books BooXtream with the capability to display to users rights information retrieved directly in the watermarked content. The existing BooXtream API will be enhanced to support:
- e-book rights and licensing information that are processed and added to the other transactional data used for the invisible e-book watermarks;
- the metadata from BooXtream are linked to the Copyright Hub;
- the rights information are inserted into the e-books in a human readable form.
When an e-book is found by the Copyright Hub, it is send to and decoded by BooXtream so that:
- the watermark is decoded and linked back to the Copyright Hub;
- the Copyright Hub can retrieve the rights information that are delivered to the end user.
For the book and journal sectors mEDRA has created a suite of tools based on the DOI (Digital Object Identifier) standard technology, that enables content owners to declare rights information on content and link it to the Web resolvable IDs that identify the content in the supply chain, i.e. the DOI or the ISBN-A (an application of the DOI to the ISBN standard).
The DOI system allows content IDs to work like links redirecting the user to a resource (e.g. the ISBN-A 10.979.12200/00000 can be resolved to https://doi.org/10.979.12200/00000); this feature is empowered to build a Rights-aware DOI suite whereby:
- the rightsholder sets the available rights (Digital Rightsholder Statement, DRS) for a book or a journal and registers a DOI on the DRS sending the rights data to mEDRA;
- the DRS is linked to the content ID (DOI or ISBN-A), making it rights-aware;
- when the final user clicks on the DOI or ISBN-A at the point of discovery of the content on the Web or in machine to machine manner (e.g. the publisher’s website, a book store, a third party platform) the DRS is displayed thanks to the management of relations between content metadata and rights metadata;
- the final user can find out if and how that content can be re-used, just clicking on its identifier that has been distributed along the content supply chain: see https://doi.org/10.979.12200/00000?locatt=type:rights.
In order for rights information to be retrieved by third parties and discovered anywhere in the Web, the rights-aware content IDs will be integrated in the Copyright Hub platform as an extra access point to rights data so that:
- an online user (human or machine) finds a textual content in the Web and resolves its ID (DOI or ISBN-A);
- the request is redirected to the Copyright Hub;
- the Hub retrieves the rights details (DRS) through rights-aware DOI;
- the DRS is returned to the user who access to the rights details.
All the technologies described above are integrated in the Copyright Hub platform that in its turn makes available existing tools for end users finding digital content in the Web or having acquired an asset, in order to interact with the Hub, i.e.:
- a Web browser plug-in, to identify content online and retrieve the links to licences or additional services from the Hub Query API;
- JavaScript used in websites via inline links, to identify content online and retrieve the links to licences or additional services from the Hub Query API.
Results
The outcomes of the ARDITO project are meant to be turned into services exploited in ARDITO ecosystem or to be used to develop other services to enable new market opportunities and automate rights and licensing services for rightsholders and content owners. On the content owner side, ARDITO opens a new way to exploit the secondary market of content through opportunities offered by licensing services or rightsholder’s copyright declarations that can be easily accessed through the Copyright Hub interface. At the other end of the value chain, this is a way for end users to easily get rights information and re-use content legally, thus minimizing the risks of copyright infringement – resulting in piracy reduction.
ARDITO will also demonstrate the effectiveness of the use of standards and interoperable technologies like the DOI and open platforms like the Copyright Hub.
In a broader sense, as expected result of the project, ARDITO aims at introducing a cross-border and cross-sector new e-infrastructure for automated management and exchange of rights data, innovating the creative sector without disrupting existing practices. Among the innovations that ARDITO will bring, the enhancement of existing identification technologies to be used for new value added services in combination to their main traditional purpose will be valuable both for providing benefits to project participants with the launch of new services, as well as for the SME sector as a whole and individual content creators, with the introduction of scalable solutions for organisations of any size. In fact, ARDITO will pilot its implementations with organisations willing to be early adopters, so to get feedback from the market during the project time frame, and in the same time will outreach the tools to the creative industries sector in order to expand the ecosystem towards an integrated Rights Data Network.
Several events in the cultural sector that ARDITO partners are attending are fruitful occasions to raise interest in the project and expand its dissemination (e.g. sector specific events, trade fairs, participation to conferences and workshops), while a set of outreach initiatives organised by ARDITO partners in the first months of the project and others planned all along the project time frame according to a defined outreach plan give the occasion to involve target organisations to pilot ARDITO tools and services and possible partners for future cooperation.
Contact details
Website: https://www.ardito-project.eu/
Email contact: ardito@medra.org












